Machines Learn Unlearning to Pole-Dance
I wrote this piece about Machine-Learning art a year ago, and set it to self-publish. Let's see how much of an idiot I look like!
First off, 'AI' doesn't exist. Some marketing team took a load of coke, then called their vision 'Open AI', because being 'Open' is good and being 'AI' is impressive. The reality is neither, and the technical meaning of this technical term remains unchanged, no matter what us unqualified plebs on the side-lines of the real research might tweet, toot, or post.
The reality is Machine Learning (ML), but ML is still cool.
When ML first managed to produce articles about the incredible art which it spat out (i.e. it produced art, and plausibly some of the articles about the art), every poor RPG designer salivated at the prospect of having actual art in their game.
Unfortunately, it didn't work for my RPGs, I don't think it works for almost any (beyond very limited capacities), and I don't think that will change any time soon.
Initial Attempts
The Vampire Child
I started with an old vampire, turned as a young man, who speaks with Ravens. The tool of choice was Midjourney.
To be as fair as possible, I left the image open to Midjourney's interpretation. My prompt was this:
dark ages boy speaks to raven in the moonlit rain

These are bad, but after many iterations, I had finally lowered my standards enough to find an okay-ish image. If you didn't mind the moon looking like a damp cloth, it would work...sort of.
Unfortunately, it didn't really illustrate anything.
The Hunter on Horseback
Next up, the vampire-hunter, who tracks down the characters, and notes their carriage's tracks veering into a village.
Slavic, of-the-night, noble hunter reading tracks, horse, footprints, village, 1300s

This worked out pretty well, assuming the horse was borrowed from Cthulhu. Otherwise, it's unusable.
He's not really 'reading tracks', he's just standing there in most iterations. And many iterations later, the image had not improved.
The General Problem
The famous ML images generally do X in the style of Y, where 'X' is a single face, and 'Y' is a prolific artist. It does this well.
However, ML doesn't seem to combine elements well. 'Optimus Prime, enjoying a sandwich', or 'Sartre explaining to Kant why Linux is the superior operating system' will stretch ML's abilities, because it fundamentally does not know what any of those words mean - it copies, and it doesn't have many copies of that sort of thing.
RPG images are meant to explain. They exist because explaining a room full of goblins lead by a half-ogre with a broad-sword, in a dungeon, isn't an easy job; but placing an image of the scene next to the writing makes the reader's job easier.
RPG images exist to explain the spells - the transformations, invocations, and prognostication - without lengthy paragraphs.
Explanation implies novelty, and every kind of ML means blending defaults with a large training set - something which immediately implies the opposite of novelty.
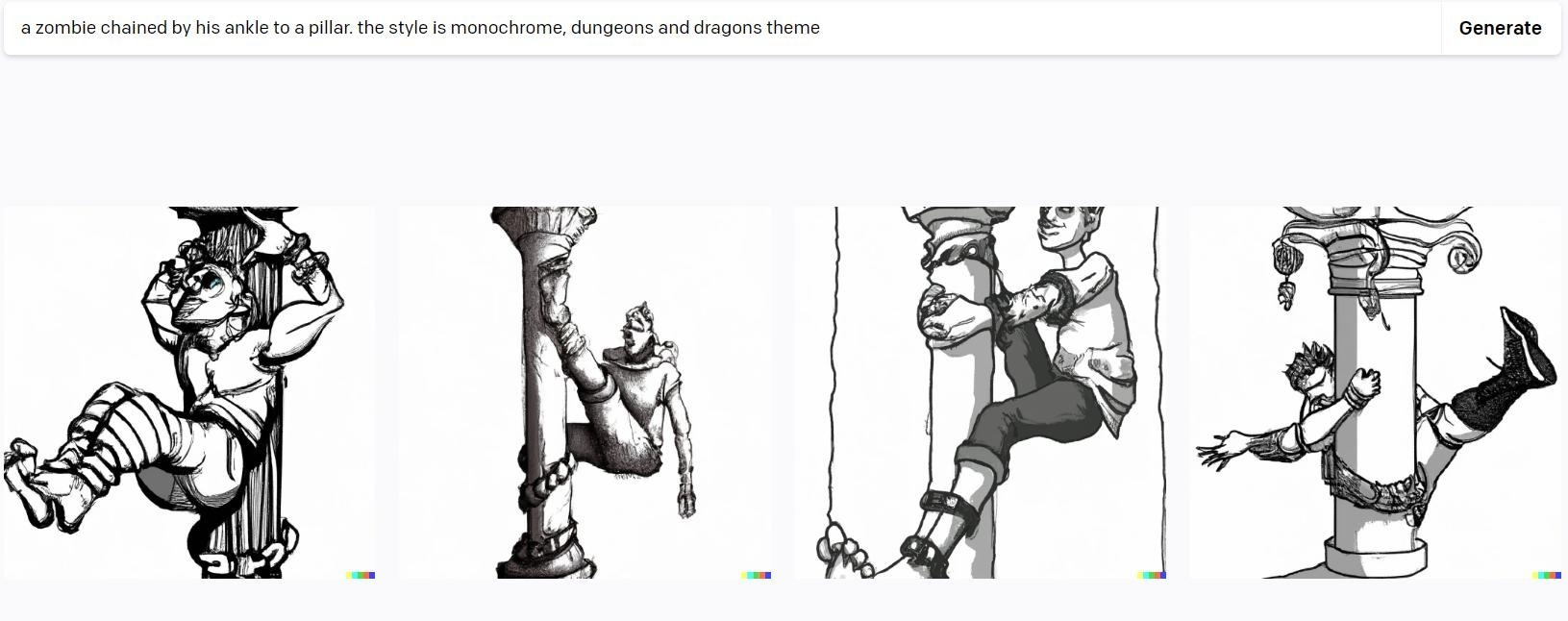
Pole Dancing Zombies
A friend challenged me on this, saying ML could make images with interacting elements, so I asked for an image from one of my modules.
Many zombies are chained to a pillar. When the PCs enter the room, they strain against the pillar, which threatens to pull the dungeon's roof in.

The results weren't great - they look like they're pole-dancing. Asking the computer specifically for 'not pole dancing' didn't help.
General Conclusions
ML cannot display novel interactions, because people create some ML tool by using not-novel source material.
ML remains an excellent tool for:
- making an image wider by a couple of centimetres (it can guess a small amount of an existing image),
- creating technically-novel stock images, and
- increasing the DPI, so small images can be printed larger, without artefacts.